3D Scene Generation
CVPR 2019 Workshop, Long Beach, CA
If you attended the workshop, please fill out our survey! This helps us improve future workshop offerings. Click here for survey
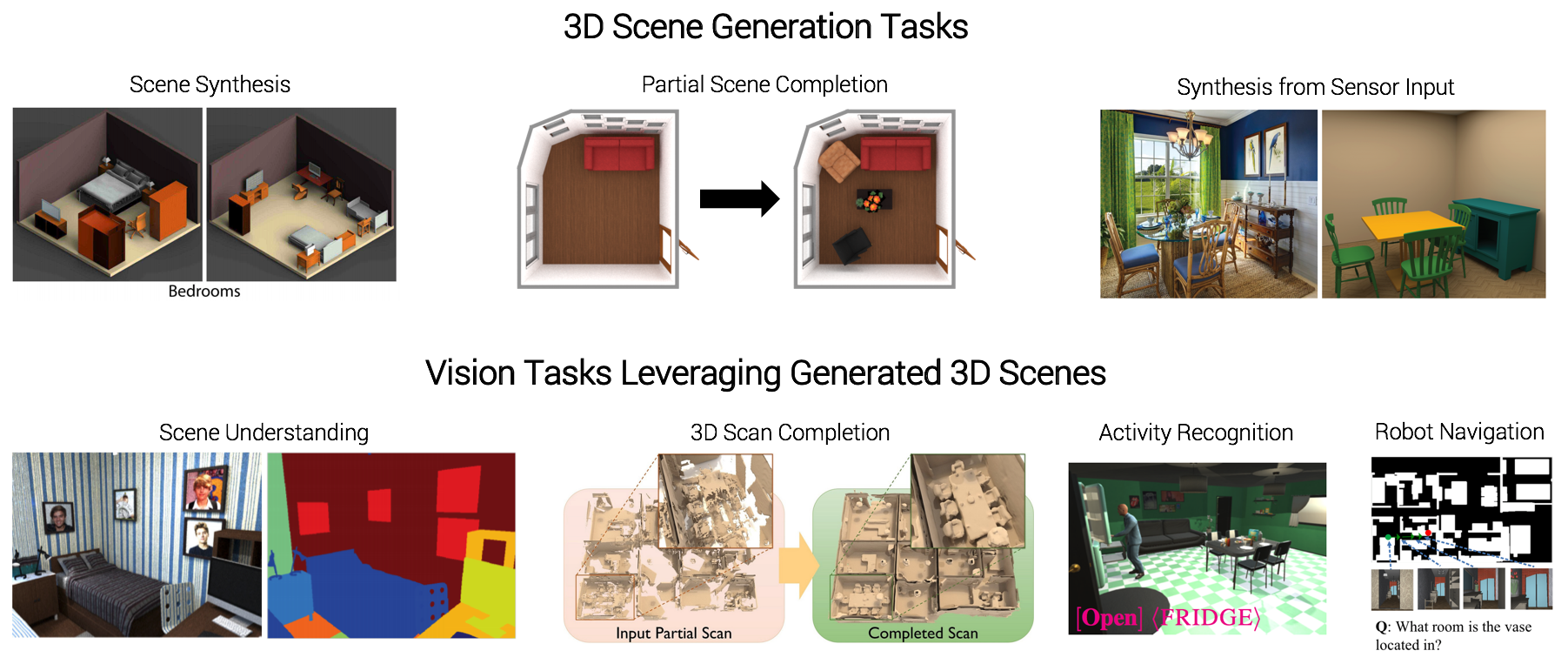
Image credit: [1, 2, 7, 12, 6, 4, 5]
Introduction
People spend a large percentage of their lives indoors---in bedrooms, living rooms, offices, kitchens, and other such spaces---and the demand for virtual versions of these real-world spaces has never been higher. Game developers, VR/AR designers, architects, and interior design firms are all increasingly making use virtual 3D scenes for prototyping and final products. Furthermore, AI/vision/robotics researchers are also turning to virtual environments to train data-hungry models for tasks such as visual navigation, 3D reconstruction, activity recognition, and more.
As the vision community turns from passive internet-images-based vision tasks to applications such as the ones listed above, the need for virtual 3D environments becomes critical. The community has recently benefited from large scale datasets of both synthetic 3D environments [13] and reconstructions of real spaces [8, 9, 14, 16], and the development of 3D simulation frameworks for studying embodied agents [3, 10, 11, 15]. While these existing datasets are a valuable resource, they are also finite in size and don't adapt to the needs of different vision tasks. To enable large-scale embodied visual learning in 3D environments, we must go beyond such static datasets and instead pursue the automatic synthesis of novel, task-relevant virtual environments.
In this workshop, we aim to bring together researchers working on automatic generation of 3D environments for computer vision research with researchers who are making use of 3D environment data for a variety of computer vision tasks. We define "generation of 3D environments" to include methods that generate 3D scenes from sensory inputs (e.g. images) or from high-level specifications (e.g. "a chic apartment for two people"). Vision tasks that consume such data include automatic scene classification and segmentation, 3D reconstruction, human activity recognition, robotic visual navigation, and more.
Call for Papers
Call for papers: We invite extended abstracts for work on tasks related to 3D scene generation or tasks leveraging generated 3D scenes. Paper topics may include but are not limited to:
- Generative models for 3D scene synthesis
- Synthesis of 3D scenes from sensor inputs (e.g., images, videos, or scans)
- Representations for 3D scenes
- 3D scene understanding based on synthetic 3D scene data
- Completion of 3D scenes or objects in 3D scenes
- Learning from real world data for improved models of virtual worlds
- Use of 3D scenes for simulation targeted to learning in computer vision, robotics, and cognitive science
Submission: we encourage submissions of up to 6 pages excluding references and acknowledgements. The submission should be in the CVPR format. Reviewing will be single blind. Accepted extended abstracts will be made publicly available as non-archival reports, allowing future submissions to archival conferences or journals. We also welcome already published papers that are within the scope of the workshop (without re-formatting), including papers from the main CVPR conference. Please submit your paper to the following address by the deadline: 3dscenegeneration@gmail.com Please mention in your email if your submission has already been accepted for publication (and the name of the conference).
Important Dates
| Paper Submission Deadline | May 17 2019 |
| Notification to Authors | May 31 2019 |
| Camera-Ready Deadline | June 7 2019 |
| Workshop Date | June 16 2019 |
Schedule
| Welcome and Introduction | 8:45am - 9:00am |
| Invited Talk 1: Daniel Aliaga | 9:00am - 9:25am |
| Invited Talk 2: Angela Dai -- "From unstructured range scans to 3d models" | 9:25am - 9:50am |
| Spotlight Talks (x3) | 9:50am - 10:05am |
| Coffee Break and Poster Session (Pacific Arena Ballroom, #24-#33) | 10:05am - 11:00am |
| Invited Talk 3: Johannes L. Schönberger -- "3D Scene Reconstruction from Unstructured Imagery" | 11:00am - 11:25am |
| Invited Talk 4: Vladlen Koltun | 11:25am - 11:50am |
| Lunch Break | 11:50am - 1:00pm |
| Industry Participant Talks | 1:00pm - 2:40pm |
| Invited Talk 5: Ellie Pavlick -- "Natural Language Understanding: Where we are stuck and where you can help" | 2:40pm - 3:05pm |
| Coffee Break and Poster Session (Pacific Arena Ballroom, #24-#33) | 3:05pm - 4:00pm |
| Invited Talk 6: Jiajun Wu | 4:00pm - 4:25pm |
| Invited Talk 7: Kristen Grauman -- "Learning to explore 3D scenes" | 4:25pm - 4:50pm |
| Invited Talk 8: Siddhartha Chaudhuri -- "Recursive neural networks for scene synthesis" | 4:50pm - 5:15pm |
| Panel Discussion and Conclusion | 5:15pm - 6:00pm |
Accepted Papers
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, Steven Lovegrove
Paper | Poster #24 AM (morning)
Ameya Phalak, Zhao Chen, Darvin Yi, Khushi Gupta, Vijay Badrinarayanan, Andrew Rabinovich
Paper | Poster #25 AM (morning)
He Wang, Sören Pirk, Ersin Yumer, Vladimir G. Kim, Ozan Sener, Srinath Sridhar, Leonidas J. Guibas
Paper | Poster #26 AM (morning)
Daniel J. Fremont, Xiangyu Yue, Tommaso Dreossi, Shromona Ghosh, Alberto L. Sangiovanni-Vincentelli, Sanjit A. Seshia
Paper | Poster #27 AM (morning)
Cheng Sun, Chi-Wei Hsiao, Min Sun, Hwann-Tzong Chen
Paper | Poster #28 AM (morning)
Timm Linder, Michael Johan Hernandez Leon, Narunas Vaskevicius, Kai O. Arras
Paper | Poster #29 AM (morning)
Krisha Mehta, Yash Kotadia
Paper
Tiago Ramalho, Tomas Kocisky, Frederic Besse, S. M. Ali Eslami, Gabor Melis, Fabio Viola, Phil Blunsom, Karl Moritz Hermann
Paper | Poster #30 AM (morning)
Xueting Li, Sifei Liu, Kihwan Kim, Xiaolong Wang, Ming-Hsuan Yang, and Jan Kautz
Paper | Poster #31 AM (morning)
Alberto Garcia-Garcia, Pablo Martinez-Gonzalez, Sergiu Oprea, John A. Castro-Vargas, Sergio Orts-Escolano, Alvaro Jover-Alvarez, Jose Garcia-Rodriguez
Paper | Poster #32 AM (morning)
Francesco Pittaluga, Sanjeev J. Koppal, Sing Bing Kang, Sudipta N. Sinha
Paper | Poster #33 AM (morning)
Zehao Yu, Jia Zheng, Dongze Lian, Zihan Zhou, Shenghua Gao
Paper | Poster #24 PM (afternoon)
Chen Liu, Kihwan Kim, Jinwei Gu, Yasutaka Furukawa, Jan Kautz
Paper | Poster #25 PM (afternoon)
Yifei Shi, Angel Xuan Chang, Zhelun Wu, Manolis Savva, Kai Xu
Paper
Xiaogang Wang, Bin Zhou, Yahao Shi, Xiaowu Chen, Qinping Zhao, Kai Xu
Paper | Poster #26 PM (afternoon)
Kuan Fang, Alexander Toshev, Li Fei-Fei, Silvio Savarese
Paper | Poster #27 PM (afternoon)
Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas J. Guibas, Hao Su
Paper | Poster #28 PM (afternoon)
Zhiqin Chen, Hao Zhang
Paper | Poster #29 PM (afternoon)
Angjoo Kanazawa, Jason Y. Zhang, Panna Felsen, Jitendra Malik
Paper | Poster #30 PM (afternoon)
Wentao Yuan, Tejas Khot, David Held, Christoph Mertz, Martial Hebert
Paper | Poster #31 PM (afternoon)
Jingwei Huang, Haotian Zhang, Li Yi, Thomas Funkhouser, Matthias Niessner, Leonidas Guibas
Paper | Poster #32 PM (afternoon)
Daniel Ritchie, Kai Wang, Yu-an Lin
Paper | Poster #33 PM (afternoon)
Invited Speakers

Vladlen Koltun is a Senior Principal Researcher and the director of the Intelligent Systems Lab at Intel. The lab is devoted to high-impact basic research on intelligent systems. Previously, he has been a Senior Research Scientist at Adobe Research and an Assistant Professor at Stanford where his theoretical research was recognized with the National Science Foundation (NSF) CAREER Award (2006) and the Sloan Research Fellowship (2007).

Kristen Grauman is a Professor in the Department of Computer Science at the University of Texas at Austin and a Research Scientist in Facebook AI Research (FAIR). Her research in computer vision and machine learning focuses on visual recognition and search. Before joining UT-Austin in 2007, she received her Ph.D. at MIT. She is an Alfred P. Sloan Research Fellow and Microsoft Research New Faculty Fellow, a recipient of NSF CAREER and ONR Young Investigator awards, the PAMI Young Researcher Award in 2013, the 2013 Computers and Thought Award from the International Joint Conference on Artificial Intelligence (IJCAI), the Presidential Early Career Award for Scientists and Engineers (PECASE) in 2013, and the Helmholtz Prize in 2017.

Johannes L. Schönberger is a Senior Scientist at the Microsoft Mixed Reality and AI lab in Zürich. He obtained his PhD in Computer Science in the Computer Vision and Geometry Group at ETH Zürich, where he was advised by Marc Pollefeys and co-advised by Jan-Michael Frahm. He received a BSc from TU Munich and an MSc from UNC Chapel Hill. In addition, he also spent time at Microsoft Research, Google, and the German Aerospace Center. His main research interests lie in robust image-based 3D modeling. More broadly, he is interested in computer vision, geometry, structure-from-motion, (multi-view) stereo, localization, optimization, machine learning, and image processing. He developed the open-source software COLMAP - an end-to-end image-based 3D reconstruction software, which achieves state-of-the-art results on recent reconstruction benchmarks.

Ellie Pavlick is an Assistant Professor of Computer Science at Brown University, and an academic partner with Google AI. She received her PhD in Computer Science from the University of Pennsylvania. She is interested in building better computational models of natural language semantics and pragmatics: how does language work, and how can we get computers to understand it the way humans do?

Daniel Aliaga does research primarily in the area of 3D computer graphics but overlaps with computer vision and visualization while also having strong multi-disciplinary collaborations outside of computer science. His research activities are divided into three groups: a) his pioneering work in the multi-disciplinary area of inverse modeling and design; b) his first-of-its-kind work in codifying information into images and surfaces, and c) his compelling work in a visual computing framework including high-quality 3D acquisition methods. Dr. Aliaga’s inverse modeling and design is particularly focused at digital city planning applications that provide innovative “what-if” design tools enabling urban stake holders from cities worldwide to automatically integrate, process, analyze, and visualize the complex interdependencies between the urban form, function, and the natural environment.

Siddhartha Chaudhuri is a Senior Research Scientist at Adobe Research, and Assistant Professor (on leave) of Computer Science and Engineering at IIT Bombay. His research focuses on richer tools for designing three-dimensional objects, particularly by novice and casual users, and on related problems in 3D shape understanding, synthesis and reconstruction. He received his PhD from Stanford University, followed by a postdoc at Princeton and a year teaching at Cornell. Apart from basic research, he is also the original author of the commercial 3D modeling package Adobe Fuse.

Angela Dai is a postdoctoral researcher at the Technical University of Munich. She received her Ph.D. in Computer Science at Stanford University advised by Pat Hanrahan. Her research focuses on 3D reconstruction and understanding with commodity sensors. She received her Masters degree from Stanford University and her Bachelors degree from Princeton University. She is a recipient of a Stanford Graduate Fellowship.

Jiajun Wu is a fifth-year PhD student at MIT, advised by Bill Freeman and Josh Tenenbaum. He received his undergraduate degree from Tsinghua University, working with Zhuowen Tu. He has also spent time at research labs of Microsoft, Facebook, and Baidu. His research has been supported by fellowships from Facebook, Nvidia, Samsung, Baidu, and Adobe. He studies machine perception, reasoning, and its interaction with the physical world, drawing inspiration from human cognition.
The workshop also features presentations by representatives of the following companies:




Organizers

Eloquent Labs, Simon Fraser University

Brown University

UT Austin

Facebook AI Research, Simon Fraser University
Acknowledgments
Thanks to visualdialog.org for the webpage format.
References
[1] Fast and Flexible Indoor Scene Synthesis via Deep Convolutional Generative Models
CoRR, vol. arXiv:1811.12463, 2018
[2] GRAINS: Generative Recursive Autoencoders for INdoor Scenes
CoRR, vol. arXiv:1807.09193, 2018
[3] Gibson env: real-world perception for embodied agents
Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on, IEEE, 2018
[4] VirtualHome: Simulating Household Activities via Programs
CVPR, 2018
[5] Embodied Question Answering
CVPR, 2018
[6] ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans
Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2018
[7] SeeThrough: Finding Objects in Heavily Occluded Indoor Scene Images
2018 International Conference on 3D Vision (3DV), 2018
[8] Matterport3D: Learning from RGB-D Data in Indoor Environments
International Conference on 3D Vision (3DV), 2017
[9] Joint 2D-3D-semantic data for indoor scene understanding
arXiv preprint arXiv:1702.01105, 2017
[10] MINOS: Multimodal Indoor Simulator for Navigation in Complex Environments
arXiv:1712.03931, 2017
[11] AI2-THOR: An interactive 3D environment for visual AI
arXiv preprint arXiv:1712.05474, 2017
[12] Physically-Based Rendering for Indoor Scene Understanding Using Convolutional Neural Networks
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
[13] Semantic scene completion from a single depth image
Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), 2017
[14] ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes
Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2017
[15] CARLA: An Open Urban Driving Simulator
1–16, Proceedings of the 1st Annual Conference on Robot Learning, 2017
[16] SceneNN: A Scene Meshes Dataset with aNNotations
International Conference on 3D Vision (3DV), 2016